
第一步:使用IK-Analyzer。把分析器的文件夹上传到服务器。

第二步:需要把分析器的jar包添加到solr工程中。
[root@bogon IK Analyzer 2012FF_hf1]# cp IKAnalyzer2012FF_u1.jar /usr/local/solr/tomcat/webapps/solr/WEB-INF/lib/
第三步:需要把IKAnalyzer需要的扩展词典及停用词词典、配置文件复制到solr工程的classpath。
classpath目录:/usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
[root@bogon IK Analyzer 2012FF_hf1]# cp IKAnalyzer.cfg.xml ext_stopword.dic mydict.dic /usr/local/solr/tomcat/webapps/solr/WEB-INF/classes
注意:扩展词典及停用词词典的字符集必须是utf-8。不能使用windows记事本编辑。
第四步:配置fieldType。需要在solrhome/solr/collection1/conf/schema.xml中配置。
技巧:使用vi、vim跳转到文档开头gg。跳转到文档末尾:G
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>

业务字段判断标准:
1、在搜索时是否需要在此字段上进行搜索。例如:商品名称、商品的卖点、商品的描述
2、后续的业务是否需要用到此字段。例如:商品id。

重新启动tomcat
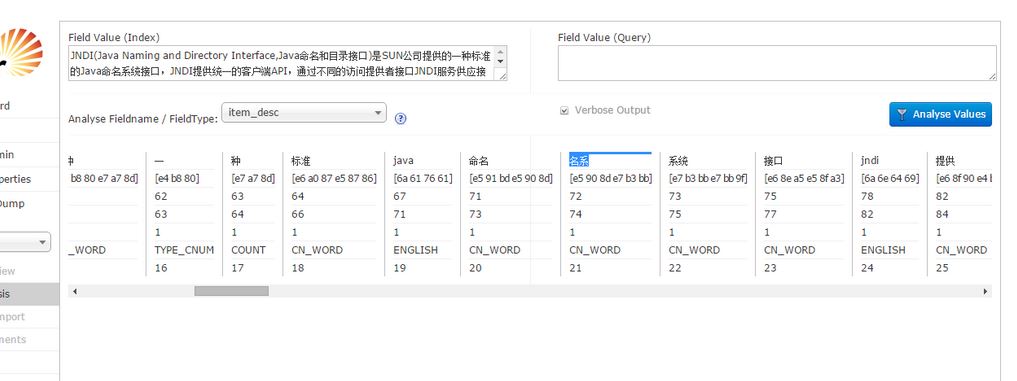
以上就是配置好了分词器。
运行solr是个很简单的事,如何让solr高效运行你的项目,这个就不容易了。
要考虑的因素太多。这里很重要一个就是对solr的配置要了解。懂得配置文件每个配置项的含义,这样操作起来就会如鱼得水!
在solr里面主要的就是solr的主目录下面的schema.xml,solrConfig.xml。
solrconfig.xml,主要定义solr的处理程序(handler)和一些扩展程序;
schema.xml,主要定义索引的字段和字段类型。
接下来的工作就是在fields结点内定义具体的字段(类似数据库中的字段),就是filed。
filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等等。
例:
<fields>
<field name="id" type="integer" indexed="true" stored="true" required="true" />
<field name="name" type="text" indexed="true" stored="true" />
<field name="summary" type="text" indexed="true" stored="true" />
<field name="author" type="string" indexed="true" stored="true" />
<field name="date" type="date" indexed="false" stored="true" />
<field name="content" type="text" indexed="true" stored="false" />
<field name="keywords" type="keyword_text" indexed="true" stored="false" multiValued="true" />
<field name="all" type="text" indexed="true" stored="false" multiValued="true"/>
</fields>
field的定义相当重要,有几个技巧需注意一下,对可能存在多值得字段尽量设置 multiValued属性为true,避免建索引是抛出错误;如果不需要存储相应字段值,尽量将stored属性设为false。
copyField(复制字段)
建议建立了一个拷贝字段,将所有的全文字段复制到一个字段中,以便进行统一的检索:
<field name="all" type="text" indexed="true" stored="false" multiValued="true"/>
并在拷贝字段结点处完成拷贝设置:
<copyField source="name" dest="all"/>
<copyField source="summary" dest="all"/>
注:“拷贝字段”就是查询的时候不用再输入:userName:张三 and userProfile:张三的个人简介。
直接可以输入"张三"就可以将“名字”含“张三”或者“简介”中含“张三”的又或者“名字”和“简介”都含有“张三”的查询出来。
他将需要查询的内容放在了一个字段中,并且默认查询该字段设为该字段就行了。