
前两天总结一下邮箱格式的正则表达式,写了一个脚本来判断输入的邮箱地址是否符合邮箱的格式。在网上找资料的时候,发现基本都是用Python和Java来做爬虫,当然Python的居多。本着学习的心态,既然得到了邮箱地址有效性的判断,那就顺便用脚本写一个抓取网页邮箱的爬虫吧。
豆瓣上着了一个网页,是一个人发起了一项活动,让大家留下邮箱,然后和陌生人进行邮箱通信,增加温暖。(也是很感性呢),不过现在的人们越来越离不开手机了,在这个活动中也许能找到以往那种陌生的温暖呢。网页网址是:https://www.douban.com/group/topic/41562980/?start=0。大家可以进去看看,也可以参加进去,离开手机一会。

找到网页之后,下一步就是写脚本了。

脚本解释:
第5行:www是获取网址,把含有邮箱地址的网址输入。
第6行:用curl来抓取网页内容,并下载到文件2data.txt里面。
第7行:取得上一步文件的所有行数,方便做循环。
第8-11行:这个For循环就是遍历所有行,并且把包含邮箱的行重定向到文件1return.txt里面。其中:sed是打印指定的行,egrep是过滤出包含邮箱地址的行。为什么用egrep而不用grep呢,有兴趣的朋友参考我的博客,Linux shell验证邮箱合法性。
执行之后,给大家看一下那两个文件:
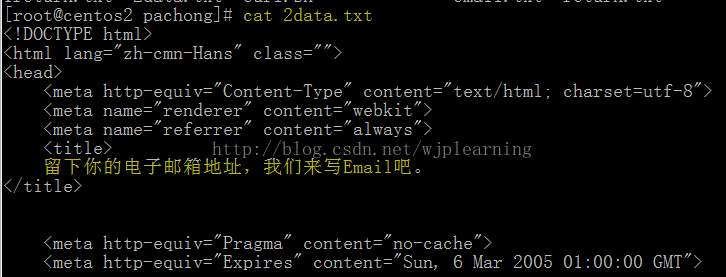
为了保护隐私允许我自行打码。

暂时初步拿到了邮箱,但是含有邮箱的文件里面还是好多东西,我们可以进一步的清理。观察发现,包含邮箱的行基本都是<p calss="">邮箱地址,我们可以通过sed命令把邮箱地址前面的<p calss="">给删除,怎么来做呢?
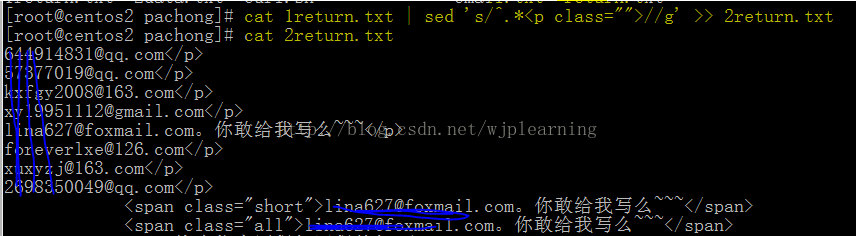
可以看到,大部分邮箱前面的部分给清理掉了,但是我们还发现后面还有好多是</p>结尾的,然后我们可以再一次使用sed命令把后面的部分删除(其实这一步是可以和上一步通过管道|命令一次执行的)。
当然上述步骤只是清理大部分内容,还有些则是需要人工干预的。经过一番努力,最后就可以得到你期望的邮箱地址了。
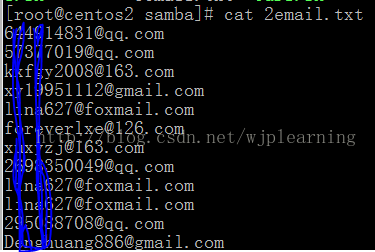
格式完美,于是我想我也要给这些人发邮件,传递时间陌生人之间的温暖,于是把文件通过Samba共享(下次更新Samba共享)到Windows里面去了。打开之后我就纳闷了,效果如下:

在Linux下明明是一行行多么整齐,怎么到了Windows就成了一行了呢?后来经过查阅资料发现,原来是因为Linux和Windows下文件换行的符号是不一样的,Windows下换行是"\r\n",而Linux下是"\n",Mac下是"\r"。所以在Windows下打开Linux系统的文件只显示了一行。
那怎么让才能让windows下打开Linux的文件正常的显示呢?
我们可以通过一个命令转换一下就可以了,那就是unix2dos:将具有unix格式的文件转换为Windows下的格式。这个命令还有一个双胞胎弟弟:dos2unix:它的功能和哥哥的功能正相反。
命令格式:unix2dos(dos2unix)
[-kh] oldfile newfile
-k 保留源文件的mtime(使用这个选项后面不用加newfile)
-h 保留原来的旧文件,并将转换后的文件输出到新文件
如果Linux上没有这个命令,安装一下就可以了:yum install -y unix2dos.
安装好之后开始转换:

转换之后的效果:
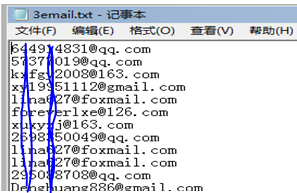
这样就看着舒服多了呢。
总结:Linux shell脚本呢主要用于监控运维,当然从上面来看爬取网页其实也是蛮简洁的,只需要几行代码就OK了,但是后续的处理可就稍微复杂一些。往后学了Java和Python之后,然后再写一下Java和Python的爬虫对比一下。对爬取邮箱做个全面的总结。今天就到这了,明天总结Samba下Linux和Windows的文件共享。