
问题描述
平台用Python开发,使用pydoop对HDFS文件进行操作,当迁移到AWS时,出现Segmentation Fault。通过排查,确定问题是因为调用了Pydoop对hdfs的初始化过程中出现的问题。
相关代码如下:
from pydoop.hdfs import fs;
print fs.hdfs()
通过gdb调试,错误信息如下:
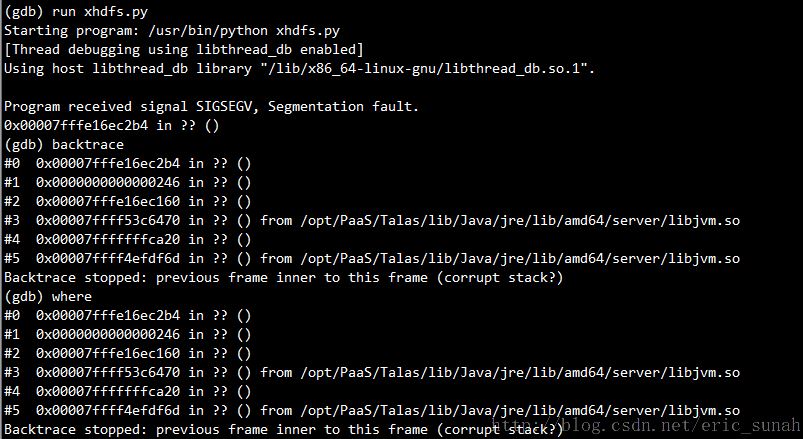
问题原因
通过查阅资料,初步判断是由于堆栈溢出导致的异常,通过查看native_core_hdfs源码,发现该代码会从LIBHDFS_OPTS读取JVM配置信息,但是环境中缺少该变量的定义.通过添加该变量,问题得到解决。
解决方案
1,在环境中增加下列变量的配置
export LIBHDFS_OPTS="-server -Xss2m -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m"
2,因为Spark中也有相关操作,所以还需要在spark/conf/spark-env.sh中增加该变量的配置:
export LIBHDFS_OPTS="-server -Xss2m -Xms2000m -Xmx2000m -Xmn800m -XX:PermSize=64m -XX:MaxPermSize=256m"