
这是并发服务器系列的第三节。第一节 介绍了阻塞式编程,第二节:线程 探讨了多线程,将其作为一种可行的方法来实现服务器并发编程。
另一种常见的实现并发的方法叫做 事件驱动编程,也可以叫做 异步 编程 注1 。这种方法变化万千,因此我们会从最基本的开始,使用一些基本的 API 而非从封装好的高级方法开始。本系列以后的文章会讲高层次抽象,还有各种混合的方法。
本系列的所有文章:
第一节 - 简介(http://www.linuxdiyf.com/linux/32842.html)
第二节 - 线程(http://www.linuxdiyf.com/linux/32844.html)
第三节 - 事件驱动(本文)
阻塞式 vs. 非阻塞式 I/O
作为本篇的介绍,我们先讲讲阻塞和非阻塞 I/O 的区别。阻塞式 I/O 更好理解,因为这是我们使用 I/O 相关 API 时的“标准”方式。从套接字接收数据的时候,调用 recv 函数会发生 阻塞,直到它从端口上接收到了来自另一端套接字的数据。这恰恰是第一部分讲到的顺序服务器的问题。
因此阻塞式 I/O 存在着固有的性能问题。第二节里我们讲过一种解决方法,就是用多线程。哪怕一个线程的 I/O 阻塞了,别的线程仍然可以使用 CPU 资源。实际上,阻塞 I/O 通常在利用资源方面非常高效,因为线程就等待着 —— 操作系统将线程变成休眠状态,只有满足了线程需要的条件才会被唤醒。
非阻塞式 I/O 是另一种思路。把套接字设成非阻塞模式时,调用 recv 时(还有 send,但是我们现在只考虑接收),函数返回的会很快,哪怕没有接收到数据。这时,就会返回一个特殊的错误状态 注2 来通知调用者,此时没有数据传进来。调用者可以去做其他的事情,或者尝试再次调用 recv 函数。
示范阻塞式和非阻塞式的 recv 区别的最好方式就是贴一段示例代码。这里有个监听套接字的小程序,一直在 recv 这里阻塞着;当 recv 返回了数据,程序就报告接收到了多少个字节 注3 :
int main(int argc, const char** argv) {
setvbuf(stdout, NULL, _IONBF, 0);
int portnum = 9988;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Listening on port %d\n", portnum);
int sockfd = listen_inet_socket(portnum);
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
while (1) {
uint8_t buf[1024];
printf("Calling recv...\n");
int len = recv(newsockfd, buf, sizeof buf, 0);
if (len < 0) {
perror_die("recv");
} else if (len == 0) {
printf("Peer disconnected; I'm done.\n");
break;
}
printf("recv returned %d bytes\n", len);
}
close(newsockfd);
close(sockfd);
return 0;
}
主循环重复调用 recv 并且报告它返回的字节数(记住 recv 返回 0 时,就是客户端断开连接了)。试着运行它,我们会在一个终端里运行这个程序,然后在另一个终端里用 nc 进行连接,发送一些字符,每次发送之间间隔几秒钟:
$ nc localhost 9988
hello # wait for 2 seconds after typing this
socket world
^D # to end the connection>
监听程序会输出以下内容:
$ ./blocking-listener 9988
Listening on port 9988
peer (localhost, 37284) connected
Calling recv...
recv returned 6 bytes
Calling recv...
recv returned 13 bytes
Calling recv...
Peer disconnected; I'm done.
现在试试非阻塞的监听程序的版本。这是代码:
int main(int argc, const char** argv) {
setvbuf(stdout, NULL, _IONBF, 0);
int portnum = 9988;
if (argc >= 2) {
portnum = atoi(argv[1]);
}
printf("Listening on port %d\n", portnum);
int sockfd = listen_inet_socket(portnum);
struct sockaddr_in peer_addr;
socklen_t peer_addr_len = sizeof(peer_addr);
int newsockfd = accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
if (newsockfd < 0) {
perror_die("ERROR on accept");
}
report_peer_connected(&peer_addr, peer_addr_len);
// 把套接字设成非阻塞模式
int flags = fcntl(newsockfd, F_GETFL, 0);
if (flags == -1) {
perror_die("fcntl F_GETFL");
}
if (fcntl(newsockfd, F_SETFL, flags | O_NONBLOCK) == -1) {
perror_die("fcntl F_SETFL O_NONBLOCK");
}
while (1) {
uint8_t buf[1024];
printf("Calling recv...\n");
int len = recv(newsockfd, buf, sizeof buf, 0);
if (len < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
usleep(200 * 1000);
continue;
}
perror_die("recv");
} else if (len == 0) {
printf("Peer disconnected; I'm done.\n");
break;
}
printf("recv returned %d bytes\n", len);
}
close(newsockfd);
close(sockfd);
return 0;
}
这里与阻塞版本有些差异,值得注意:
accept 函数返回的 newsocktfd 套接字因调用了 fcntl, 被设置成非阻塞的模式。
检查 recv 的返回状态时,我们对 errno 进行了检查,判断它是否被设置成表示没有可供接收的数据的状态。这时,我们仅仅是休眠了 200 毫秒然后进入到下一轮循环。
同样用 nc 进行测试,以下是非阻塞监听器的输出:
$ ./nonblocking-listener 9988
Listening on port 9988
peer (localhost, 37288) connected
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
recv returned 6 bytes
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
Calling recv...
recv returned 13 bytes
Calling recv...
Calling recv...
Calling recv...
Peer disconnected; I'm done.
作为练习,给输出添加一个时间戳,确认调用 recv 得到结果之间花费的时间是比输入到 nc 中所用的多还是少(每一轮是 200 ms)。
这里就实现了使用非阻塞的 recv 让监听者检查套接字变为可能,并且在没有数据的时候重新获得控制权。换句话说,用编程的语言说这就是 轮询 —— 主程序周期性的查询套接字以便读取数据。
对于顺序响应的问题,这似乎是个可行的方法。非阻塞的 recv 让同时与多个套接字通信变成可能,轮询这些套接字,仅当有新数据到来时才处理。就是这样,这种方式 可以 用来写并发服务器;但实际上一般不这么做,因为轮询的方式很难扩展。
首先,我在代码中引入的 200ms 延迟对于演示非常好(监听器在我输入 nc 之间只打印几行 “Calling recv...”,但实际上应该有上千行)。但它也增加了多达 200ms 的服务器响应时间,这无意是不必要的。实际的程序中,延迟会低得多,休眠时间越短,进程占用的 CPU 资源就越多。有些时钟周期只是浪费在等待,这并不好,尤其是在移动设备上,这些设备的电量往往有限。
但是当我们实际这样来使用多个套接字的时候,更严重的问题出现了。想像下监听器正在同时处理 1000 个客户端。这意味着每一个循环迭代里面,它都得为 这 1000 个套接字中的每一个 执行一遍非阻塞的 recv,找到其中准备好了数据的那一个。这非常低效,并且极大的限制了服务器能够并发处理的客户端数。这里有个准则:每次轮询之间等待的间隔越久,服务器响应性越差;而等待的时间越少,CPU 在无用的轮询上耗费的资源越多。
讲真,所有的轮询都像是无用功。当然操作系统应该是知道哪个套接字是准备好了数据的,因此没必要逐个扫描。事实上,就是这样,接下来就会讲一些 API,让我们可以更优雅地处理多个客户端。
select
select 的系统调用是可移植的(POSIX),是标准 Unix API 中常有的部分。它是为上一节最后一部分描述的问题而设计的 —— 允许一个线程可以监视许多文件描述符 注4 的变化,而不用在轮询中执行不必要的代码。我并不打算在这里引入一个关于 select 的全面教程,有很多网站和书籍讲这个,但是在涉及到问题的相关内容时,我会介绍一下它的 API,然后再展示一个非常复杂的例子。
select 允许 多路 I/O,监视多个文件描述符,查看其中任何一个的 I/O 是否可用。
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
readfds 指向文件描述符的缓冲区,这个缓冲区被监视是否有读取事件;fd_set 是一个特殊的数据结构,用户使用 FD_* 宏进行操作。writefds 是针对写事件的。nfds 是监视的缓冲中最大的文件描述符数字(文件描述符就是整数)。timeout 可以让用户指定 select 应该阻塞多久,直到某个文件描述符准备好了(timeout == NULL 就是说一直阻塞着)。现在先跳过 exceptfds。
select 的调用过程如下:
在调用之前,用户先要为所有不同种类的要监视的文件描述符创建 fd_set 实例。如果想要同时监视读取和写入事件,readfds 和 writefds 都要被创建并且引用。
用户可以使用 FD_SET 来设置集合中想要监视的特殊描述符。例如,如果想要监视描述符 2、7 和 10 的读取事件,在 readfds 这里调用三次 FD_SET,分别设置 2、7 和 10。
select 被调用。
当 select 返回时(现在先不管超时),就是说集合中有多少个文件描述符已经就绪了。它也修改 readfds 和 writefds 集合,来标记这些准备好的描述符。其它所有的描述符都会被清空。
这时用户需要遍历 readfds 和 writefds,找到哪个描述符就绪了(使用 FD_ISSET)。
作为完整的例子,我在并发的服务器程序上使用 select,重新实现了我们之前的协议。完整的代码在这里;接下来的是代码中的重点部分及注释。警告:示例代码非常复杂,因此第一次看的时候,如果没有足够的时间,快速浏览也没有关系。
使用 select 的并发服务器
使用 I/O 的多发 API 诸如 select 会给我们服务器的设计带来一些限制;这不会马上显现出来,但这值得探讨,因为它们是理解事件驱动编程到底是什么的关键。
最重要的是,要记住这种方法本质上是单线程的 注5 。服务器实际上在 同一时刻只能做一件事。因为我们想要同时处理多个客户端请求,我们需要换一种方式重构代码。
首先,让我们谈谈主循环。它看起来是什么样的呢?先让我们想象一下服务器有一堆任务,它应该监视哪些东西呢?两种类型的套接字活动:
新客户端尝试连接。这些客户端应该被 accept。
已连接的客户端发送数据。这个数据要用 第一节 中所讲到的协议进行传输,有可能会有一些数据要被回送给客户端。
尽管这两种活动在本质上有所区别,我们还是要把它们放在一个循环里,因为只能有一个主循环。循环会包含 select 的调用。这个 select 的调用会监视上述的两种活动。
这里是部分代码,设置了文件描述符集合,并在主循环里转到被调用的 select 部分。
// “master” 集合存活在该循环中,跟踪我们想要监视的读取事件或写入事件的文件描述符(FD)。
fd_set readfds_master;
FD_ZERO(&readfds_master);
fd_set writefds_master;
FD_ZERO(&writefds_master);
// 监听的套接字一直被监视,用于读取数据,并监测到来的新的端点连接。
FD_SET(listener_sockfd, &readfds_master);
// 要想更加高效,fdset_max 追踪当前已知最大的 FD;这使得每次调用时对 FD_SETSIZE 的迭代选择不是那么重要了。
int fdset_max = listener_sockfd;
while (1) {
// select() 会修改传递给它的 fd_sets,因此进行拷贝一下再传值。
fd_set readfds = readfds_master;
fd_set writefds = writefds_master;
int nready = select(fdset_max + 1, &readfds, &writefds, NULL, NULL);
if (nready < 0) {
perror_die("select");
}
...
这里的一些要点:
由于每次调用 select 都会重写传递给函数的集合,调用器就得维护一个 “master” 集合,在循环迭代中,保持对所监视的所有活跃的套接字的追踪。
注意我们所关心的,最开始的唯一那个套接字是怎么变成 listener_sockfd 的,这就是最开始的套接字,服务器借此来接收新客户端的连接。
select 的返回值,是在作为参数传递的集合中,那些已经就绪的描述符的个数。select 修改这个集合,用来标记就绪的描述符。下一步是在这些描述符中进行迭代。
...
for (int fd = 0; fd <= fdset_max && nready > 0; fd++) {
// 检查 fd 是否变成可读的
if (FD_ISSET(fd, &readfds)) {
nready--;
if (fd == listener_sockfd) {
// 监听的套接字就绪了;这意味着有个新的客户端连接正在联系
...
} else {
fd_status_t status = on_peer_ready_recv(fd);
if (status.want_read) {
FD_SET(fd, &readfds_master);
} else {
FD_CLR(fd, &readfds_master);
}
if (status.want_write) {
FD_SET(fd, &writefds_master);
} else {
FD_CLR(fd, &writefds_master);
}
if (!status.want_read && !status.want_write) {
printf("socket %d closing\n", fd);
close(fd);
}
}
这部分循环检查 可读的 描述符。让我们跳过监听器套接字(要浏览所有内容,看这个代码) 然后看看当其中一个客户端准备好了之后会发生什么。出现了这种情况后,我们调用一个叫做 on_peer_ready_recv 的 回调 函数,传入相应的文件描述符。这个调用意味着客户端连接到套接字上,发送某些数据,并且对套接字上 recv 的调用不会被阻塞 注6 。这个回调函数返回结构体 fd_status_t。
typedef struct {
bool want_read;
bool want_write;
} fd_status_t;
这个结构体告诉主循环,是否应该监视套接字的读取事件、写入事件,或者两者都监视。上述代码展示了 FD_SET 和 FD_CLR 是怎么在合适的描述符集合中被调用的。对于主循环中某个准备好了写入数据的描述符,代码是类似的,除了它所调用的回调函数,这个回调函数叫做 on_peer_ready_send。
现在来花点时间看看这个回调:
typedef enum { INITIAL_ACK, WAIT_FOR_MSG, IN_MSG } ProcessingState;
#define SENDBUF_SIZE 1024
typedef struct {
ProcessingState state;
// sendbuf 包含了服务器要返回给客户端的数据。on_peer_ready_recv 句柄填充这个缓冲,
// on_peer_read_send 进行消耗。sendbuf_end 指向缓冲区的最后一个有效字节,
// sendptr 指向下个字节
uint8_t sendbuf[SENDBUF_SIZE];
int sendbuf_end;
int sendptr;
} peer_state_t;
// 每一端都是通过它连接的文件描述符(fd)进行区分。只要客户端连接上了,fd 就是唯一的。
// 当客户端断开连接,另一个客户端连接上就会获得相同的 fd。on_peer_connected 应该
// 进行初始化,以便移除旧客户端在同一个 fd 上留下的东西。
peer_state_t global_state[MAXFDS];
fd_status_t on_peer_ready_recv(int sockfd) {
assert(sockfd < MAXFDs);
peer_state_t* peerstate = &global_state[sockfd];
if (peerstate->state == INITIAL_ACK ||
peerstate->sendptr < peerstate->sendbuf_end) {
// 在初始的 ACK 被送到了客户端,就没有什么要接收的了。
// 等所有待发送的数据都被发送之后接收更多的数据。
return fd_status_W;
}
uint8_t buf[1024];
int nbytes = recv(sockfd, buf, sizeof buf, 0);
if (nbytes == 0) {
// 客户端断开连接
return fd_status_NORW;
} else if (nbytes < 0) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// 套接字 *实际* 并没有准备好接收,等到它就绪。
return fd_status_R;
} else {
perror_die("recv");
}
}
bool ready_to_send = false;
for (int i = 0; i < nbytes; ++i) {
switch (peerstate->state) {
case INITIAL_ACK:
assert(0 && "can't reach here");
break;
case WAIT_FOR_MSG:
if (buf[i] == '^') {
peerstate->state = IN_MSG;
}
break;
case IN_MSG:
if (buf[i] == '$') {
peerstate->state = WAIT_FOR_MSG;
} else {
assert(peerstate->sendbuf_end < SENDBUF_SIZE);
peerstate->sendbuf[peerstate->sendbuf_end++] = buf[i] + 1;
ready_to_send = true;
}
break;
}
}
// 如果没有数据要发送给客户端,报告读取状态作为最后接收的结果。
return (fd_status_t){.want_read = !ready_to_send,
.want_write = ready_to_send};
}
peer_state_t 是全状态对象,用来表示在主循环中两次回调函数调用之间的客户端的连接。因为回调函数在客户端发送的某些数据时被调用,不能假设它能够不停地与客户端通信,并且它得运行得很快,不能被阻塞。因为套接字被设置成非阻塞模式,recv 会快速的返回。除了调用 recv, 这个句柄做的是处理状态,没有其它的调用,从而不会发生阻塞。
举个例子,你知道为什么这个代码需要一个额外的状态吗?这个系列中,我们的服务器目前只用到了两个状态,但是这个服务器程序需要三个状态。
来看看 “套接字准备好发送” 的回调函数:
fd_status_t on_peer_ready_send(int sockfd) {
assert(sockfd < MAXFDs);
peer_state_t* peerstate = &global_state[sockfd];
if (peerstate->sendptr >= peerstate->sendbuf_end) {
// 没有要发送的。
return fd_status_RW;
}
int sendlen = peerstate->sendbuf_end - peerstate->sendptr;
int nsent = send(sockfd, peerstate->sendbuf, sendlen, 0);
if (nsent == -1) {
if (errno == EAGAIN || errno == EWOULDBLOCK) {
return fd_status_W;
} else {
perror_die("send");
}
}
if (nsent < sendlen) {
peerstate->sendptr += nsent;
return fd_status_W;
} else {
// 所有东西都成功发送;重置发送队列。
peerstate->sendptr = 0;
peerstate->sendbuf_end = 0;
// 如果我们现在是处于特殊的 INITIAL_ACK 状态,就转变到其他状态。
if (peerstate->state == INITIAL_ACK) {
peerstate->state = WAIT_FOR_MSG;
}
return fd_status_R;
}
}
这里也一样,回调函数调用了一个非阻塞的 send,演示了状态管理。在异步代码中,回调函数执行的很快是受争议的,任何延迟都会阻塞主循环进行处理,因此也阻塞了整个服务器程序去处理其他的客户端。
用脚步再来运行这个服务器,同时连接 3 个客户端。在一个终端中我们运行下面的命令:
$ ./select-server
在另一个终端中:
$ python3.6 simple-client.py -n 3 localhost 9090
INFO:2017-09-26 05:29:15,864:conn1 connected...
INFO:2017-09-26 05:29:15,864:conn2 connected...
INFO:2017-09-26 05:29:15,864:conn0 connected...
INFO:2017-09-26 05:29:15,865:conn1 sending b'^abc$de^abte$f'
INFO:2017-09-26 05:29:15,865:conn2 sending b'^abc$de^abte$f'
INFO:2017-09-26 05:29:15,865:conn0 sending b'^abc$de^abte$f'
INFO:2017-09-26 05:29:15,865:conn1 received b'bcdbcuf'
INFO:2017-09-26 05:29:15,865:conn2 received b'bcdbcuf'
INFO:2017-09-26 05:29:15,865:conn0 received b'bcdbcuf'
INFO:2017-09-26 05:29:16,866:conn1 sending b'xyz^123'
INFO:2017-09-26 05:29:16,867:conn0 sending b'xyz^123'
INFO:2017-09-26 05:29:16,867:conn2 sending b'xyz^123'
INFO:2017-09-26 05:29:16,867:conn1 received b'234'
INFO:2017-09-26 05:29:16,868:conn0 received b'234'
INFO:2017-09-26 05:29:16,868:conn2 received b'234'
INFO:2017-09-26 05:29:17,868:conn1 sending b'25$^ab0000$abab'
INFO:2017-09-26 05:29:17,869:conn1 received b'36bc1111'
INFO:2017-09-26 05:29:17,869:conn0 sending b'25$^ab0000$abab'
INFO:2017-09-26 05:29:17,870:conn0 received b'36bc1111'
INFO:2017-09-26 05:29:17,870:conn2 sending b'25$^ab0000$abab'
INFO:2017-09-26 05:29:17,870:conn2 received b'36bc1111'
INFO:2017-09-26 05:29:18,069:conn1 disconnecting
INFO:2017-09-26 05:29:18,070:conn0 disconnecting
INFO:2017-09-26 05:29:18,070:conn2 disconnecting
和线程的情况相似,客户端之间没有延迟,它们被同时处理。而且在 select-server 也没有用线程!主循环 多路 处理所有的客户端,通过高效使用 select 轮询多个套接字。回想下 第二节中 顺序的 vs 多线程的客户端处理过程的图片。对于我们的 select-server,三个客户端的处理流程像这样:
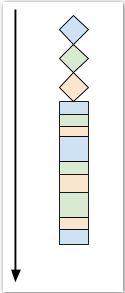
所有的客户端在同一个线程中同时被处理,通过乘积,做一点这个客户端的任务,然后切换到另一个,再切换到下一个,最后切换回到最开始的那个客户端。注意,这里没有什么循环调度,客户端在它们发送数据的时候被客户端处理,这实际上是受客户端左右的。
同步、异步、事件驱动、回调
select-server 示例代码为讨论什么是异步编程、它和事件驱动及基于回调的编程有何联系,提供了一个良好的背景。因为这些词汇在并发服务器的(非常矛盾的)讨论中很常见。
让我们从一段 select 的手册页面中引用的一句话开始:
select,pselect,FD_CLR,FD_ISSET,FD_SET,FD_ZERO - 同步 I/O 处理
因此 select 是 同步 处理。但我刚刚演示了大量代码的例子,使用 select 作为 异步 处理服务器的例子。有哪些东西?
答案是:这取决于你的观察角度。同步常用作阻塞处理,并且对 select 的调用实际上是阻塞的。和第 1、2 节中讲到的顺序的、多线程的服务器中对 send 和 recv 是一样的。因此说 select 是 同步的 API 是有道理的。可是,服务器的设计却可以是 异步的,或是 基于回调的,或是 事件驱动的,尽管其中有对 select 的使用。注意这里的 on_peer_* 函数是回调函数;它们永远不会阻塞,并且只有网络事件触发的时候才会被调用。它们可以获得部分数据,并能够在调用过程中保持稳定的状态。
如果你曾经做过一些 GUI 编程,这些东西对你来说应该很亲切。有个 “事件循环”,常常完全隐藏在框架里,应用的 “业务逻辑” 建立在回调上,这些回调会在各种事件触发后被调用,用户点击鼠标、选择菜单、定时器触发、数据到达套接字等等。曾经最常见的编程模型是客户端的 JavaScript,这里面有一堆回调函数,它们在浏览网页时用户的行为被触发。
select 的局限
使用 select 作为第一个异步服务器的例子对于说明这个概念很有用,而且由于 select 是很常见、可移植的 API。但是它也有一些严重的缺陷,在监视的文件描述符非常大的时候就会出现。
有限的文件描述符的集合大小。
糟糕的性能。
从文件描述符的大小开始。FD_SETSIZE 是一个编译期常数,在如今的操作系统中,它的值通常是 1024。它被硬编码在 glibc 的头文件里,并且不容易修改。它把 select 能够监视的文件描述符的数量限制在 1024 以内。曾有些人想要写出能够处理上万个并发访问的客户端请求的服务器,所以这个问题很有现实意义。有一些方法,但是不可移植,也很难用。
糟糕的性能问题就好解决的多,但是依然非常严重。注意当 select 返回的时候,它向调用者提供的信息是 “就绪的” 描述符的个数,还有被修改过的描述符集合。描述符集映射着描述符“就绪/未就绪”,但是并没有提供什么有效的方法去遍历所有就绪的描述符。如果只有一个描述符是就绪的,最坏的情况是调用者需要遍历 整个集合 来找到那个描述符。这在监视的描述符数量比较少的时候还行,但是如果数量变的很大的时候,这种方法弊端就凸显出了 注7 。
由于这些原因,为了写出高性能的并发服务器, select 已经不怎么用了。每一个流行的操作系统有独特的不可移植的 API,允许用户写出非常高效的事件循环;像框架这样的高级结构还有高级语言通常在一个可移植的接口中包含这些 API。
epoll
举个例子,来看看 epoll,Linux 上的关于高容量 I/O 事件通知问题的解决方案。epoll 高效的关键之处在于它与内核更好的协作。不是使用文件描述符,epoll_wait 用当前准备好的事件填满一个缓冲区。只有准备好的事件添加到了缓冲区,因此没有必要遍历客户端中当前 所有 监视的文件描述符。这简化了查找就绪的描述符的过程,把空间复杂度从 select 中的 O(N) 变为了 O(1)。
关于 epoll API 的完整展示不是这里的目的,网上有很多相关资源。虽然你可能猜到了,我还要写一个不同的并发服务器,这次是用 epool 而不是 select。完整的示例代码 在这里。实际上,由于大部分代码和 用 select 的服务器相同,所以我只会讲要点,在主循环里使用 epoll:
struct epoll_event accept_event;
accept_event.data.fd = listener_sockfd;
accept_event.events = EPOLLIN;
if (epoll_ctl(epollfd, EPOLL_CTL_ADD, listener_sockfd, &accept_event) < 0) {
perror_die("epoll_ctl EPOLL_CTL_ADD");
}
struct epoll_event* events = calloc(MAXFDS, sizeof(struct epoll_event));
if (events == NULL) {
die("Unable to allocate memory for epoll_events");
}
while (1) {
int nready = epoll_wait(epollfd, events, MAXFDS, -1);
for (int i = 0; i < nready; i++) {
if (events[i].events & EPOLLERR) {
perror_die("epoll_wait returned EPOLLERR");
}
if (events[i].data.fd == listener_sockfd) {
// 监听的套接字就绪了;意味着新客户端正在连接。
...
} else {
// A peer socket is ready.
if (events[i].events & EPOLLIN) {
// 准备好了读取
...
} else if (events[i].events & EPOLLOUT) {
// 准备好了写入
...
}
}
}
}
通过调用 epoll_ctl 来配置 epoll。这时,配置监听的套接字数量,也就是 epoll 监听的描述符的数量。然后分配一个缓冲区,把就绪的事件传给 epoll 以供修改。在主循环里对 epoll_wait 的调用是魅力所在。它阻塞着,直到某个描述符就绪了(或者超时),返回就绪的描述符数量。但这时,不要盲目地迭代所有监视的集合,我们知道 epoll_write 会修改传给它的 events 缓冲区,缓冲区中有就绪的事件,从 0 到 nready-1,因此我们只需迭代必要的次数。
要在 select 里面重新遍历,有明显的差异:如果在监视着 1000 个描述符,只有两个就绪, epoll_waits 返回的是 nready=2,然后修改 events 缓冲区最前面的两个元素,因此我们只需要“遍历”两个描述符。用 select 我们就需要遍历 1000 个描述符,找出哪个是就绪的。因此,在繁忙的服务器上,有许多活跃的套接字时 epoll 比 select 更加容易扩展。
剩下的代码很直观,因为我们已经很熟悉 “select 服务器” 了。实际上,“epoll 服务器” 中的所有“业务逻辑”和 “select 服务器” 是一样的,回调构成相同的代码。
这种相似是通过将事件循环抽象分离到一个库/框架中。我将会详述这些内容,因为很多优秀的程序员曾经也是这样做的。相反,下一篇文章里我们会了解 libuv,一个最近出现的更加受欢迎的时间循环抽象层。像 libuv 这样的库让我们能够写出并发的异步服务器,并且不用考虑系统调用下繁琐的细节。
注1:我试着在做网络浏览和阅读这两件事的实际差别中突显自己,但经常做得头疼。有很多不同的选项,从“它们是一样的东西”到“一个是另一个的子集”,再到“它们是完全不同的东西”。在面临这样主观的观点时,最好是完全放弃这个问题,专注特殊的例子和用例。
注2:POSIX 表示这可以是 EAGAIN,也可以是 EWOULDBLOCK,可移植应用应该对这两个都进行检查。
注3:和这个系列所有的 C 示例类似,代码中用到了某些助手工具来设置监听套接字。这些工具的完整代码在这个 仓库 的 utils 模块里。
注4:select 不是网络/套接字专用的函数,它可以监视任意的文件描述符,有可能是硬盘文件、管道、终端、套接字或者 Unix 系统中用到的任何文件描述符。这篇文章里,我们主要关注它在套接字方面的应用。
注5:有多种方式用多线程来实现事件驱动,我会把它放在稍后的文章中进行讨论。
注6:由于各种非实验因素,它 仍然 可以阻塞,即使是在 select 说它就绪了之后。因此服务器上打开的所有套接字都被设置成非阻塞模式,如果对 recv 或 send 的调用返回了 EAGAIN 或者 EWOULDBLOCK,回调函数就装作没有事件发生。阅读示例代码的注释可以了解更多细节。
注7:注意这比该文章前面所讲的异步轮询的例子要稍好一点。轮询需要 一直 发生,而 select 实际上会阻塞到有一个或多个套接字准备好读取/写入;select 会比一直询问浪费少得多的 CPU 时间。