
作为DBA,具备一定的Linux服务器性能监控知识也是很有必要的。有时在服务器性能瓶颈导致Oracle数据库性能问题,也就是说在Oracle视角来看几乎没有什么等待或alert log里的错误跟踪,但系统还是缓慢或用户反馈系统响应时间相对平时的正常状态还是明显的差异,这时我们不放尝试如下方法来观察操作系统问题。
Linux服务器性能监控是管理员很重要的工作,服务器运行应该提供最优化的网络性能。在性能突然低于平均的情况,问题可能来自于正在执行的进程、内存使用率、磁盘性能、网络流量和CPU负载等情况。因此,理解和优化系统性能是很重要的工作。工作的过程是先检查整个系统的状态,然后检查特定的子系统。
Linux服务器整体性能监控:
CPU监控
进程监控
内存监控
网络监控
i/o监控
性能监控的方法:
1、/proc
Linux系统为管理员提供了非常好的方法,使其可以在系统运行时候,在线修改内核参数,而不需要重新引导,这就是通过/proc虚拟文件系统实现的。/proc虚拟文件系统是一种内核和内核模块之间用来向进程发送消息的机制。该文件系统允许与内核数据结构进行交互,获得有关内核和进程的交互信息。与其他文件系统不同,/proc存在于内存中而不是磁盘中。
/proc文件系统文件及目录与的定义:
目录名称 目录内容
apm 高级电源管理信息
cmdline 内核命令行
Cpuinfo 关于Cpu信息
Devices 可以用到的设备(块设备/字符设备)
Dma 使用的DMA通道
Filesystems 支持的文件系统
Interrupts 中断的使用
Ioports I/O端口的使用
Kcore 内核核心印象
Kmsg 内核消息
Ksyms 内核符号表
Loadavg 负载均衡
Locks 内核锁
Meminfo 内存信息
Misc 杂项
Modules 加载模块列表
Mounts 加载的文件系统
Partitions 系统识别的分区表
Rtc 实时时钟
Slabinfo Slab池信息
Stat 全面统计状态表
Swaps 对换空间的利用情况
Version 内核版本
Uptime 系统正常运行时间
并不是所有这些目录在你的系统中都有,这取决于你的内核配置和装载的模块。另外,在 /proc下还有三个很重要的目录:net,scsi和sys。 Sys目录是可写的,可以通过它来访问或修改内核的参数(见下一部分),而net和scsi则依赖于内核配置。例如,如果系统不支持scsi,则scsi 目录不存在。
除了以上介绍的这些,还有的是一些以数字命名的目录,它们是进程目录。系统中当前运行的每一个进程都有对应的一个目录在/proc下,以进程的 PID号为目录名,它们是读取进程信息的接口。而self目录则是读取进程本身的信息接口,是一个link。Proc文件系统的名字就是由之而起。进程目录的结构如下:
cmdline 命令行参数
environ 环境变量值
fd 一个包含所有文件描述符的目录
Mem 进程的内存被利用情况
Stat 进程状态
Status 进程当前状态,以可读的方式显示出来
Cwd 当前工作目录的链接
Exe 指向该进程的执行命令文件
Maps 内存映象
Statm 进程内存状态信息
Root 链接此进程的root目录
用户如果要查看系统信息,可以用cat命令。例如:
# cat /proc/interrupts
要改变内核的参数,只要用echo参数重定向到文件中即可。但是必须很小心,因为可能会造成系统崩溃。最好是先找一台无关紧要的机子,调试成功后再应用到你的系统上。下面有一个例子:
# cat /proc/sys/fs/file-max
4096
# echo 8192 > /proc/sys/fs/file-max
# cat /proc/sys/fs/file-max
8192
如果你优化了参数,则可以把它们写成添加到文件rc.local中,使它在系统启动时自动完成修改。
Proc虚拟文件系统功能:
1. 进程信息:系统中任何一个进程,在对应的子目录中都有一个同名的进程ID,可以找到cmdline,mem,root,stat,statm,status。
2. 系统信息:如果需要了解整个熊信息,可以从/proc/stat文件中获得。其中包括cpu占用、磁盘空间、内存页、内存兑换、中断、开关、自举时间等。
3. CPU信息:利用/proc/cpuinfo文件可以获得cpu当前准确的信息。
4. 负载信息:/proc/loadavg包含系统负载信息。
5. 内存信息:meminfo包含系统内存的详细信息。其中显示物理内存的数量,可用交换空间数量,闲置内存数量等。
监测系统负载
1、使用uptime命令
使用uptime命令可以查看系统负载,系统平均负载被定义为在特定的时间间隔内运行队列中的平均进程数目。如果一个进程在没有等待i/o操作的结果并主动进入等待状态,则其位于运行的队列中。
[root@kt-db2 proc]# uptime
00:51:59 up 49 days, 17:33, 3 users, load average: 7.04, 7.83, 9.44
上面显示最近1分钟内系统平均负载时7.04,最近5分钟平均负载是 7.83,最近15分钟平均负载是 9.44。
2、ps命令
linux系统提供了ps及top等工具查看系统进程信息的系统调用。结合这些系统调用可以清晰的了解进程运行状态,从而采取措施来确保linux系统的性能。他们是目前最常见的进程状态查看工具,随着linux发行版一起安装使用。下面是ps命令输出的例子
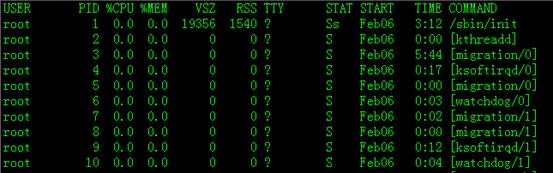
PID:进程ID
%CPU: CPU负载
%MEM:内存占用百分比
VSZ(Virtual Memory Size):进程可占用的内存地址空间大小
RSS(Resident Set Size):进程实际占用的内存地址空间大小
但要注意的是:RSS中包括了共享库占用的内存大小,如libc等,我们可以通过pmap命令看到进程调用各种库占用的内存大小:
pmap -d pid
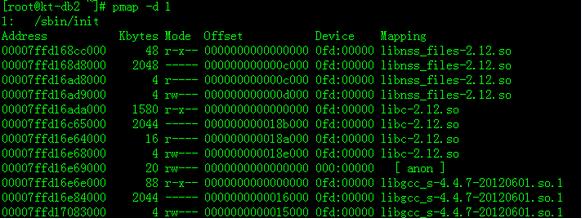
其中r-x--部分属于代码段,在各个进程之间共享。rw---属于数据段,这才是这个进程真正使用的内存。
TTY:次终端号
STAT:进程状态
START:启动进程时间
TIME:进程消耗CPU时间
COMMAND:进程名
3、监测内存使用情况
使用free命令可以监控内存使用情况:


以上数字单位为KB,其中32G内存总空间,30G交换空间,第三行显示物理内存。Free列显示没有使用的内存,shared显示共享内存,buffers显示缓存,默认情况下,使用k为单位,可以指定-m参数,使用M单位来进行统计。组合watch命令和free命令用来实时监控内存的使用情况:
#watch –n 1 –d free

使用top命令监控CPU、内存状态
#top
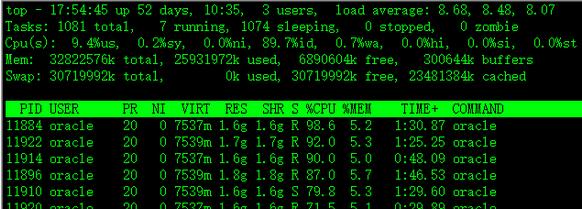
Top命令输出第一行显示系统更新的时间,1分钟、5分钟、15分钟平均负载;第二行显示所有的进程,包括目前运行的进程(Run)、挂起的进程(Sleep)、僵尸进程(Zombie)和停止的进程(Stop)。第三行显示CPU的使用情况,包括内核空间占用、用户空间占用的比例以及IDLE的比例。第五行和第六行显示当前物理内存和虚拟内存的使用情况。
Top输出标识:
PID:进程ID
USER:进程所有者
PRI:进程优先级别
NI:进程优先级别数值
VIRT:进程需要占用的物理内存值
RES:进程实际占用的物理内存值
SHR:进程占用共享内存值
S:进程当前使用CPU状态
%CPU:进程当前CPU使用率
%MEM:进程占用物理内存百分比
TIME+:进程启动后,占用总的CPU时间
COMMAND:进程名
5、使用iostat监控i/o性能
目前Linux服务器主要性能瓶颈在于i/o,主要是由于i/o系统性能的提高远低于CPU、内存等性能的提高。根据摩尔定律,18个月,CPU性能和内存容量就能翻一番。但是作为外部存储设备---磁盘,由于机械运动的本质,导致性能提供非常有限,每年约为7%提高。Iostat监视磁盘的工作状态,统统是显示CPU的使用情况。Iostat命令的格式如下:
Iostat [-c|-d] [-k] [-t] [-v][-x][device][interval[count]]
-c:显示CPU使用情况
-d:显示磁盘使用情况
-k:每秒k字节显示数据
-t:打印report时间
-v:打印版本信息和用户发
-x device:指定要统计的设备名称,默认所有设备
Interval:指定每次统计时间间隔,count指定按照这个时间间隔统计的次数。
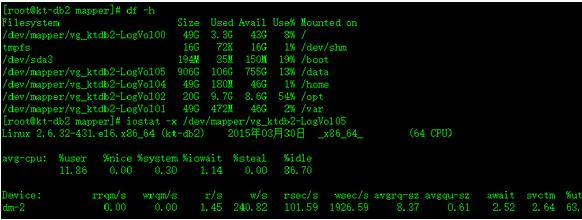
Iostat输出标识:
Device:监测设备名称
rrqm/s:每秒需要读取操作数
wrqm/s:每秒需要写入操作数
r/s:每秒实际读的操作数
w/s:每秒实际写的操作数
rsec/s:每秒读取扇区数
wsec/s:每秒写入扇区数
rkB/s:每秒实际读取的大小,单位KB
wkB/s:每秒实际写入的大小,单位KB
avgrq-sz:需求平均大小区段
avgqu-sz:需求平均队列长度
await:等待i/o的平均时间,单位ms
svctm:i/o需求完成的平均时间
%until:被i/o消耗的实际的CPU时间。
sar工具:系统活动状态报告
sar语法如下:
sar [-option] [-o file] t [n]
该命令每t秒采样一次,共采样n次,其中-o file标示采样结果以二进制的形式保存到file文件中,option选项如下:
-A:通过读取/var/log/sar目录下的所有文件分类显示所有的历史数据
-b:通过读取设备的I/O中断读取设备的吞吐量
-B:报告内存和虚拟内存交换统计
-c:报告每秒创建的进程数
-d:报告物理设备的写入和读取的信息,可以和-p一起使用
-f:从二进制文件读取内容,如sar –f file
-n:分析网络状态统计,后面可以跟DEV,EDEV,NFS,NFSD以及SOCK等例如-n DEV
-o:把统计信息写入文件
-P:报告每个处理器的应用统计,用于多处理器
-p:显示友好设备名,方面查看
-r:内存和交换区占用统计
-u:报告cpu利用率参数
-v:报告inode,文件或者其他内核表资源占用信息
-w:报告系统交换信息,每次交换数据的次数
-W:报告系统交换吞吐量
-x:用于监控进程,指定PID
-X:用户监控子进程,指定一个子进程的ID
下面的例子每秒刷新1次CPU利用率,共刷新3次:
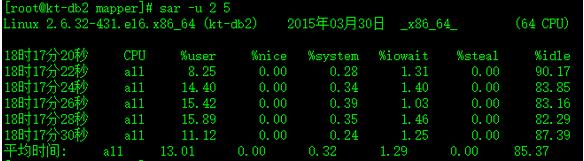
CPU:CPU编号
%user:用户模式中运行程序所花的时间
%nice:运行正常进程所花的时间
%system:内核空间所占用的时间
%iowait:没有进程在CPU上执行,处理器等待i/o完成的时间
%steal:?
%idle:进程在CPU上执行的时间
vmstat工具
vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息。由 vmstat 命令生成的报告可以用于平衡系统负载活动。系统范围内的这些统计信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
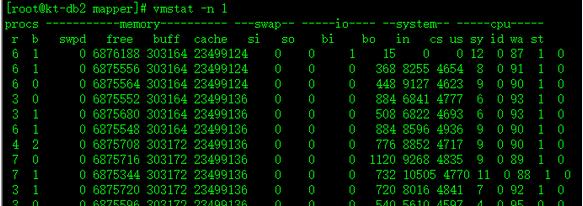
r:可运行进程的数量
b:阻塞进程的数量
swpd:已用交换空间的数量
free:自由RAM数量
buff:缓冲RAM的数量
cache:缓存RAM的数量
si:从磁盘分页到内存的数量
so:从内存分页到磁盘的数量
bi:从磁盘读取的块数
bo:写入磁盘的块
in:系统中断
cs:进程上下文开关
us:用户模式
sy:系统模式
wa:等待I/O
id:空闲
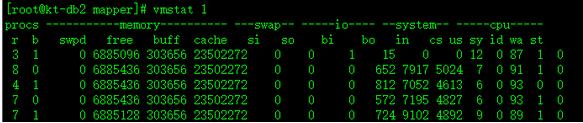
vmstat监控性能实例:
其中si和so两列都是0,说明swap没有真的i/0,设备的性能不会受到影响。
在sysctl中有个参数:vm.swappiness默认为60,在内存足够的时候,建议设置成0,这样可以尽量避免Linux 主动使用swap空间。
注:以上图片上传到红联Linux系统教程频道中。