
Linux 持续进军可伸缩计算领域,尤其是可扩展存储领域。 Linux 文件系统最近新增了一个引人注目的选择 —— Ceph,一个维持 POSIX 兼容的同时还集成了复制、容错的分布式文件系统。探讨 Ceph 的架构,可以知道它是如何提供容错性,及如何简化大量数据的管理的。
作为存储行业的架构师,我对文件系统情有独钟。这些系统是存储系统的用户接口,尽管它们都倾向于提供相似的特性集,它们还是会提供引人注目的不同点。Ceph 也如此,它提供了一些你会在文件系统中找到的最有趣的特性。
Ceph 始于加州大学圣克鲁兹分校的 Sage Weil 的博士学位课题。但从 2010 年 3 月下旬起,你可以 Linux 主流内核中找到 Ceph (从 2.6.34 内核起)。
尽管 Ceph 可能还未对生产环境做好准备,但它依然有助于评估目的。本文探讨了 Ceph 文件系统,及其成为可扩展分布式存储的诱人选择的独到之处。
Ceph 目标
开发文件系统是一种复杂的投入,但是如果能准确的解决问题的话,则拥有着不可估量的价值。Ceph 的目标可以简单的定义为:
容易扩展到 PB 量级
不同负荷下的高性能 (每秒输入输出操作数 [IPOS]、带宽)
可靠性高
不幸的,这些目标彼此间矛盾(例如,可扩展性会减少或阻碍性能,或影响可靠性)。Ceph 开发了一些有趣的概念(例如动态元数据分区、数据分布、复制),本文会简单探讨。Ceph 的设计也集成了容错特性来防止单点故障,并假定,大规模(PB 级的存贮)的存储故障是一种常态,而非异常。最后,它的设计没有假定特定的工作负荷,而是包含了可变的分布式工作负荷的适应能力,从而提供最佳的性能。它以 POSIX 兼容为目标完成这些工作,允许它透明的部署于那些依赖于 POSIX 语义的现存应用(通过 Ceph 增强功能)。最后,Ceph 是开源分布式存储和 Linux 主流内核的一部分(2.6.34)。
Ceph 架构
现在,让我们先在上层探讨 Ceph 架构及其核心元素。之后深入到其它层次,来辨析 Ceph 的一些主要方面,从而进行更详细的分析。
Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据使用者)、元数据服务器(缓冲及同步分布的元数据)、对象存储集群(以对象方式存储数据与元数据,实现其它主要职责),及集群监控(实现监控功能)。
图 1. Ceph 生态系统的概念架构
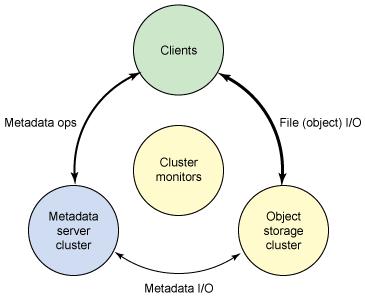
如图一所示,客户端通过元数据服务器来执行元数据操作(以识别数据位置)。元数据服务器管理数据的位置及新数据的存储位置。注意,元数据存储在存储集群中(如 "Metadata I/O" 所示)。真正的文件 I/O 发生在客户端和对象存储集群之间。以这种方式,较高级的 POSIX 功能(如 open、close、rename)由元数据服务器管理,与此同时,POSIX 功能(如 read、write)直接由对象存储集群管理。
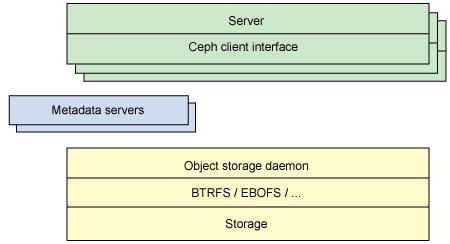
图2 提供了架构的另一视角图。一组服务器通过客户端接口访问 Ceph 生态系统,接口理解元数据服务器和对象级存储的关系。这种分布式存储系统可被看作为几层,包括存储设备的格式(扩展的和基于 B-树 的对象文件系统[ebofs],或者其它备选),为管理数据复制、故障检测、恢复、后续数据迁移(称之为可靠的自发分布式对象存储,RADOS)等所设计的至关重要的管理层。最后,监控用于鉴定组件故障,包括后续通知。
图2. Ceph 生态系统的简化分层视图
Ceph 组件
了解了 Ceph 的概念构图之后,你可以继续深入了解 Ceph 生态系统内实现的主要组件。Ceph 和传统文件系统一个关键的不同是,智能并非集中于文件系统本身,而是分布在生态系统各处。
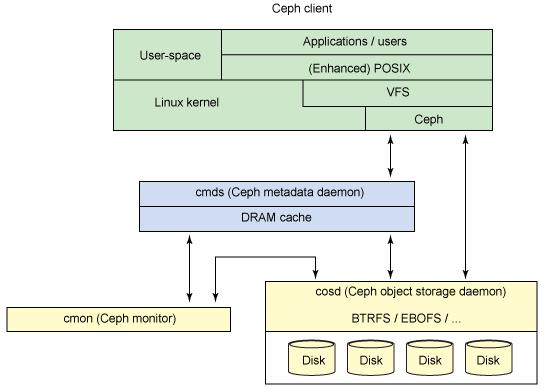
图 3 展示了一个简单的 Ceph 生态系统。Ceph 客户端是 Ceph 文件系统的使用者。Ceph 元数据后台服务程序提供了元数据服务,而 Ceph 对象存储后台服务程序提供了实际的存储(数据及元数据)。最后, Ceph 监控提供了集群的管理。注意可以存在多个 Ceph 客户端,多个对象存储端点,许多元数据服务器(取决于文件系统的能力),和至少一对冗余监控。这样的话,这个文件系统是怎样实现分布的呢?
图 3. 简单的 Ceph 生态系统
Ceph 客户端
因为 Linux 为文件系统提供了一个通用接口(通过虚拟文件系统交换器 [VFS]),Ceph 的用户视角是透明的。考虑到多个服务器组成存储系统的可能性(详见关于创建 Ceph 集群的 资源[http://www.ibm.com/developerworks/linux/library/l-ceph/index.html?ca=dgr-lnxw01CEPHdth-LX#resources] 一节),管理员视角当然会不同。从使用者的视角看,他们可以使用海量存储系统,并不知晓下层的元数据服务器、监控、聚合成大规模存储池的各个对象存储设备。使用者仅仅看到一个挂载点,从那里执行标准的文件 I/O 操作。
Ceph 文件系统 — 或者至少是客户端接口 — 在 Linux 内核中实现。注意绝大多数文件系统,所有的控制和智能都实现在内核的文件系统源代码本身中。但对 Ceph 而言,文件系统的智能分布在各节点上,它简化了客户端接口,但也同时提供给 Ceph 应对大规模(甚至动态的)数据的能力。
并非是依赖于分配链(用来映射磁盘块到指定文件的元数据),Ceph 使用了一个有趣的选择。一个文件从 Linux 的角度看,被赋予了一个来自元数据服务器的 inode 号(INO),它是文件的唯一识别符。之后这个文件被刻进到多个对象中(基于文件大小)。使用 INO 和 对象号 (ONO),每个对象被赋予了一个对象 ID(OID)。通过使用 OID 上的一个简单哈希,每个对象被分配到 一个放置组中。这个放置组(通过 PGID 来识别)是对象的概念上的容器。最后,放置组到对象存储设备的映射是一种使用了称为可扩展哈希受控复制(CRUSH)算法的伪随机映射。以这种方式,放置组(及副本)映射到存储设备不依赖于任何元数据,而是依赖于伪随机映射函数。这种行为是理想的,因为它最小化了存储的负荷,以及简化了数据的分布和查询。
最后一个分配组件是集群映射。集群映射是代表着存储集群的设备的有效表示。通过 PGID 和 集群映射,你可以定位任何对象。
Ceph 元数据服务器
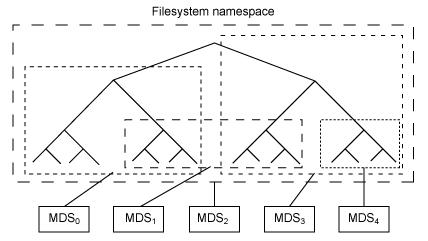
元数据服务器的任务 (命令) 是管理文件系统的命名空间。尽管不管是数据还是元数据都存储在对象存储集群中,它们都被分别管理,以支持可扩展性。事实上,元数据在元数据服务器的集群间进一步的分割,这些元数据服务器能够自适应的复制和散布命名空间,从而避免热点。如图 4所示,元数据服务器管理部分命名空间,并能部分重叠(出于冗余及性能的考虑)。从元数据服务器到命名空间的映射,在 Ceph 中通过动态子树分区的方式来执行,它允许 Ceph 在保留本地性能的同时可以适应变化的工作负荷(在元数据服务器间迁移命名空间)。
图 4. Ceph 元数据服务器命名空间的分区
注:以上图片上传到红联Linux系统教程频道中。
但因为每个元数据服务器就客户端的个数而言只简单的管理命名空间,它主要的应用程序是智能元数据缓冲(因为实际的元数据最终存储在对象存储集群中)。写入的元数据被缓冲在短期的日志中,它最终会被推送到物理存储里。这种行为允许元数据服务器可以立即对客户端提供最新的元数据服务(这在元数据操作中很常见)。日志对故障恢复也很有用:如果元数据服务器失效,它的日志能被重播,以确保元数据安全的保存到磁盘上。
元数据服务器管理 inode 空间,进行文件名到元数据的转换。元数据服务器转换文件名到 inode 节点,文件大小,以及分割 Ceph 客户端用于文件 I/O 的数据(布局)。
Ceph 监控
Ceph 包括了实现集群映射管理功能的监控,但一些容错管理的要素实现于对象存储本身。当对象存储设备失效,或者新的设备被添加,监控检测并维持一个有效的集群映射。这个功能以分布式的方式执行,在这里,更新映射会与当前的流量状况进行沟通。Ceph 使用了 Paxos,它是分布式一致性的一系列算法。
Ceph 对象存储
与传统对象存储相似,Ceph 存储节点不仅包含了存储,也包含了智能。传统的驱动器是的简单目标端,仅仅响应发起端的命令。而对象存储设备是智能设备,既可以作为目标端,也可以作为发起端,从而支持通讯以及其它对象存储设备的协同。
从存储的角度看,Ceph对象存储提供了从“对象”到“块”的映射(传统上这个事情在客户端的文件系统层来做)。这个行为允许本地实体对如何来存储对象做出最好的选择。早期的Ceph版本使用了一个在本地文件系统上的自定义的底层文件系统(EBOFS)。这个系统实现了一个非标准接口的底层存储来提供对象语义和其他特征(如对磁盘提交的异步通知)。现在可以在存储节点上使用B-tree文件系统(BTRFS),它已经实现了一些必要的功能(如嵌入式完整性)。因为Ceph客户端使用CRUSH,而不知道磁盘上文件的块映射信息, 所以底层的存储设备可以安全的管理从对象到块的映射。 这使得,当设备被发现失效后,依然节点复制数据。失效恢复的分布式机制也提升了存储系统的扩展性,因为失效检测和恢复在整个生态系统得到分布。Ceph中称之为RADOS(见图3)。
其它有趣的特性
似乎是文件系统的动态自适应的天性不足,Ceph 也实现了一些对使用者可见的有趣特性。例如,用户可以在 Ceph 的任何子目录下(包括其全部内容),创建快照。也可以在任何子目录级进行文件和容量记账,它可以报告存储大小和任何指定子目录的文件数(及其所有的嵌套内容)。
Ceph 现状与未来
尽管 Ceph 现在集成到 Linux 主流内核中,它被准确的描述为实验性的。这种状态的文件系统有助于评估,但还没有为生产环境做好准备。但考虑到 Ceph 被 Linux 内核所采用,以及发起人持续开发的动力,它应该在不久后就可以用于解决你的大规模存储的需要。
其它分布式文件系统
Ceph 在分布式文件系统领域并不是独一无二的,但它在管理大规模存储的生态系统的方式上是独特的。其它的分布式文件系统,如包括 Google 文件系统(GFS),通用并行文件系统(GPFS),和 Lustre,仅举几例。随着海量级别存储的独特挑战的引入,Ceph 背后的理念看起来像是为分布式文件系统提供了一种有趣的未来。
展望
Ceph 不仅仅是文件系统,更是一个带有企业级特性的对象存储的生态系统。在 资源[http://www.ibm.com/developerworks/linux/library/l-ceph/index.html?ca=dgr-lnxw01CEPHdth-LX#resources] 一节中,你会发现关于如何建立一个简单的 Ceph 集群(包括元数据服务器、对象服务器、监控)的信息。Ceph 在分布式存储方面填补了空白,看到这个开源软件在未来如何演进也将是很有趣的。